
Разработана программная диагностическая система, предназначенная для определения у пациентов степени дисбактериоза желудочно-кишечного тракта с помощью заложенного в нее FCM-алгоритма нечеткой кластеризации.
Введение. В настоящее время нечеткие методы кластеризации широко применяются в различных сферах для решения задач интеллектуального анализа в виду того, что зачастую необходимо произвести разбиение множества объектов на несколько кластеров так, чтобы определить степень принадлежности каждого объекта каждому кластеру [1]. Такая ситуация характерна и для сферы медицины, так как по результатам анализа состояния здоровья пациента нельзя однозначно сказать, здоров он или болен. В связи с этим возникает необходимость определения его степеней принадлежности к каждому из двух кластеров.
Целью данной работы является описание разработанной программной диагностической системы на базе алгоритма нечеткой кластеризации Fuzzy C-Means (FCM), предназначенной для определения степени дисбактериоза у пациентов на основе априорных многомерных данных по состоянию микрофлоры желудочно-кишечного тракта (ЖКТ).
Постановка задачи. Пусть нам дано множество U, состоящее из N пациентов (U = {u1, u2,…,uN}), каждый из которых характеризуется вектором в N-мерном Евклидовом пространстве. Необходимо разбить данное множество на два кластера (больных и здоровых пациентов) путём определения степени принадлежности каждому из них для каждого пациента [1]. По результатам проведённого разбиения необходимо для каждого пациента в зависимости от степени его принадлежности кластеру больных определить степень дисбактериоза.
Описание алгоритма. Пусть нечеткие кластеры задаются матрицей нечеткого разбиения, имеющей следующий вид [2,3]:

где μki – степень принадлежности k-ого объекта i-му кластеру; k – номер объекта; i – номер кластера; N – количество объектов; С – количество кластеров.
При этом должно выполняться следующее условие:

На первом этапе алгоритма задаются следующие параметры алгоритма:
- С – количество кластеров;
- q – экспоненциальный вес, определяющий нечеткость кластеров (), который, как правило, принимают равным двум (q = 2), так как не существует теоретически обоснованного правила выбора его значения [2];
- ε – параметр останова алгоритма.
На втором этапе выполняется генерация начальной матрицы нечеткого разбиения (1), путем полного отнесения всех пациентов кластеру больных людей (μk1 = 1, μk2 = 0).
На третьем этапе осуществляется расчет центров кластеров по следующей формуле [3]:

где ci – центр i-го кластера; uk – вектор параметров k-ого объекта.
На четвертом этапе для каждого объекта рассчитывается расстояние, равное Евклидовой метрике, до центра каждого кластера, согласно следующей формуле [3]:

Таким образом, формируется матрица расстояний, имеющая ту же размерность, что и матрица разбиения.
На пятом этапе осуществляется пересчет элементов матрицы разбиения с учетом следующих условий [3]:

На шестом этапе проверяется следующее условие:

Если условие (6) истинно для каждой пары, алгоритм завершает свою работу, предоставляя результат в наглядном виде. Иначе осуществляется переход на третий этап [3]. Более наглядно данный алгоритм представлен на рисунке 1 в виде блок схемы.
Модель оценки и визуализации результата разбиения. По результатам кластеризации каждому пациенту ставится в соответствие балльная оценка состояния здоровья в диапазоне от 0 до 3 и цвет для визуализации результата в соответствии с табл. 1 [1].
Таблица 1. Оценка состояния пациента

Табличная модель представления результатов кластеризации. Для более детального рассмотрения полученной информации в системе предусмотрено табличное представление результата кластеризации, в рамках которого отображаются точные значения полученных степеней принадлежности объекта кластерам, а также, экспертные и назначенные оценки состояния пациента. Данная модель представления результатов необходима в виду того, что графическое представление результата не может предоставить пользователю точное значение степени принадлежности объекта кластеру [1].
Таким образом, результаты нечеткого разбиения на два кластера дополнительно сведены в таблицу, в которой присутствуют следующие колонки:
Номер пациента;
- Степень принадлежности объекта кластеру больных людей;
- Степень принадлежности объекта кластеру здоровых людей;
- Экспертная оценка состояния пациента в интервале [0;3];
- Программная оценка состояния пациента в интервале [0;3].
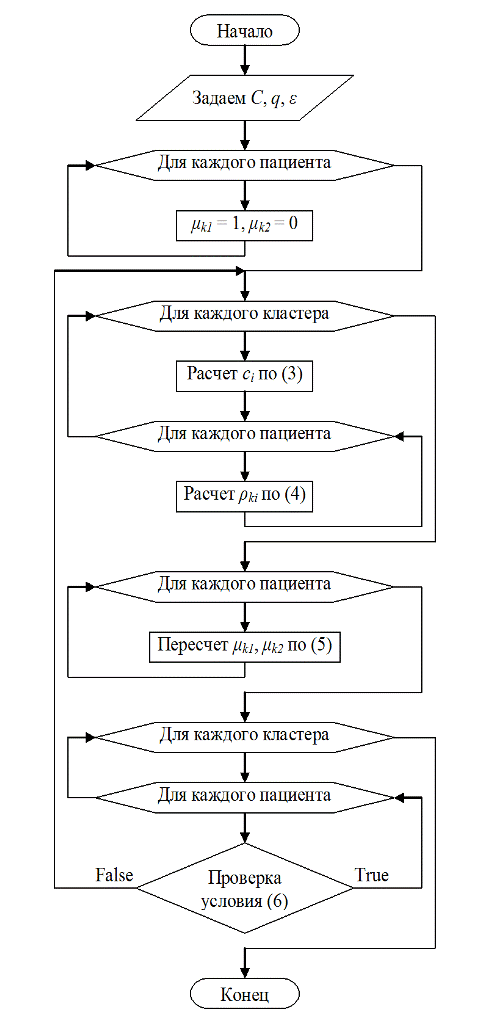
Рис. 1. Блок-схема алгоритма
Методика оценки качества разбиения. Для оценки качества полученного разбиения предложена следующая идея [1]:
- Если программная оценка совпадает с экспертной, то мы считаем такой результат положительным;
- Если программная оценка превосходит экспертную, такой результат мы считаем улучшенным;
- Если программная оценка ниже экспертной, такой результат мы считаем промахом.
Расчет качества разбиения производится по следующей формуле:

где E – количество промахов, N – общее число пациентов в выборке.
Результаты кластеризации. Для проверки работоспособности данной диагностической системы Нижегородским научно-исследовательским институтом эпидемиологии и микробиологии им. И.Н. Блохиной (ННИИЭМ) была предоставлена экспериментальная выборка, состоящая из 170 пациентов, принадлежащих одной возрастной группе (33–34 года). Состояние каждого пациента охарактеризовано априорными данными в виде набора из 29 проб на предмет анализа состояния микробиоты ЖКТ у пациента. Каждый параметр данного набора представляет собой нормированное значение в интервале [0;12]. В результате кластеризации экспериментальной выборки было получено разбиение, представленное на рисунке 2.

Рис. 2. Разбиение, полученное в результате кластеризации экспериментальной выборки
На графике вдоль оси абсцисс откладываются номера пациентов (k), а вдоль оси ординат откладываются значения степени принадлежности k-ого пациента кластеру больных людей (μk1).
Качество разбиения для данной выборки составило примерно 96%.
Также сотрудниками ННИИЭМ был проведен ряд тестов по исследованию зависимости качества разбиения от размера выборки для различных возрастных групп, результаты которых представлены в табл. 2.
Таблица 2. Результаты исследования зависимости качества разбиения от размера выборки для различных возрастных групп

По полученным результатам было установлено, что в среднем качество разбиения составляет примерно 95,55%.
Заключение. В виду того, что разработанная диагностическая система показала достаточно высокие результаты, были поставлены следующие цели по ее развитию:
- обеспечить работу со смешанными возрастными группами, путём разделения общей выборки на подмножества с учётом возраста;
- добавить экспертную часть, осуществляющую детальный анализ параметров вектора пациента и на основе полученных сведений и результата диагностики выносить рекомендации по его лечению в соответствии с заложенной базой знаний.