
Процесс сбора и предварительной обработки информации является определяющим при исследовании и моделировании медицинских систем с точки зрения качества полученных моделей. Невозможно получить объективные оценки на основе неполного или неполноценного материала. Поэтому на этапе сбора первичного материала необходимо как предварительное планирование этого процесса, так и обработка информационной базы с целью повышения качества и достоверности собранной информации.
Практика показывает, что стремление отразить большее число реально существующих факторов, различных характеристик объекта или процесса нередко не только не повышает точности решения поставленной задачи, но и делает модель достаточно громоздкой и трудно воспринимаемой. Поэтому уже на этапе исследования целесообразно четко установить, какие характеристики объекта или процесса являются наиболее существенными, а чем можно пренебречь.
Первоначально отобранные характеристики по существу нередко являются ориентировочными, и в дальнейшем иногда возникает необходимость их заменить или уточнить. Подобные коррективы приходится вносить почти на всех этапах математического моделирования, и необходимость в них, в частности, зависит от качества фактического материала.
Основную информацию, на базе которой формируются модели медицинских систем, получают путем анализа архивной и текущей информации, результатов мониторинга, изучение результатов лабораторных и клинических исследований, проведения эксперимента. Показатели, измеренные в качественной шкале, для дальнейшей обработки необходимо преобразовать в численные оценки. Аналитическим, экспериментальным или другим путем необходимо установить, какие явления доступны управлению, какие нет. Значения факторов как управляемых, так и неуправляемых могут меняться в зависимости от места и времени их приложения.
Таким образом, процесс предварительной обработки медико-статистической информации для моделирования включает следующие этапы:
1) формирование перечня исследуемых показателей;
2) преобразование качественных характеристик в количественные оценки;
3) фильтрация информации;
4) оптимизация признакового пространства.
На первом этапе формируется структура информационной базы. Экспертами устанавливается перечень показателей, описывающих исследуемую медицинскую систему. При этом, если сбор информации сопряжен с большими затратами или требуется использование инвазивных методов исследования, целесообразно сократить перечень анализируемых показателей, отобрав самые значимые. Определение значимости показателей производится на основе экспертных оценок с использованием метода априорного ранжирования.
Для дальнейшей обработки информация, содержащая фиксированные смысловые (лингвистические) значения сообщений, должна быть преобразована в численную. Преобразование предлагается осуществлять следующим образом.
Сообщения, имеющие два возможных варианта (типа «да», «нет»), преобразуются соответственно в 1 и 0.
Если сообщение может принимать более двух различных лингвистических значений ![]() , используется метод экспертных оценок. Перед N экспертами (N≥2) ставится вопрос: «Насколько значение Li более значимо, чем
, используется метод экспертных оценок. Перед N экспертами (N≥2) ставится вопрос: «Насколько значение Li более значимо, чем![]() ?» Ответы для каждой пары формируются в форме лингвистической переменной γi <сообщение Li важнее сообщения
?» Ответы для каждой пары формируются в форме лингвистической переменной γi <сообщение Li важнее сообщения ![]()
В качестве термов этой переменной определены следующие:

Для перевода к численному виду каждому значению терма ставится в соответствие число от 1 до 5. В результате по каждой паре ![]() формируется N значений переменной
формируется N значений переменной ![]()
Обобщенное значение переменной вычисляется по формуле:
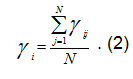
Численная оценка каждого исходного значения определяется следующим образом:
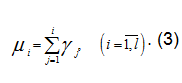
В процессе формирования базы данных, особенно при работе с архивной информацией, возникают «пробелы», обусловленные неполнотой представленных данных, при этом отсутствие даже одного показателя влечет за сбой невозможность использования при моделировании всей информации об объекте. Для устранения данной проблемы в случае единичных пропусков целесообразно использование аппроксимации на основе регрессионных или нейромоделей, для временных рядов – на основе экспоненциального сглаживания.
Помимо «пропусков», достаточно серьезным фактором, влияющим на качество моделирования, является наличие недостоверных данных, появившихся в силу различных объективных и субъективных причин (неточность измерения, погрешность из-за сбоя аппаратуры, ошибки в исходной документации, ошибки при внесении данных и др.). Для минимизации вероятности использования искаженной и недостоверной информации при проведении системного анализа и построении прогностических и классификационных моделей медицинских систем необходимы ее предварительный отбор или фильтрация.
Основным эвристическим правилом при информационной фильтрации является отбор информационных сообщений с наиболее вероятным, т.е. наиболее типичным для данной ситуации набором сведений.
Всю исходную информацию можно представить в виде множества объектов (пациентов – при решении задач диагностики и лечения, годовых данных по ЛПУ, району, городу, области, региону – при решении задач управления системой здравоохранения):
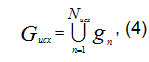
где Nисх - объем исходной выборки.
Каждый объект характеризуется набором показателей (физических, анамнестических, клинических и лабораторных – для больных; состояния здоровья, деятельности и ресурсного обеспечения – для ЛПУ и системы здравоохранения):
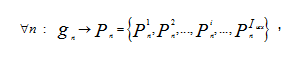
где ![]() - индекс показателя,
- индекс показателя, ![]() - порядковый номер объекта.
- порядковый номер объекта.
На первом этапе фильтрации информации для каждого показателя ![]() устанавливаются нижняя и верхняя допустимые границы
устанавливаются нижняя и верхняя допустимые границы ![]()
выход за которые возможен только из-за ошибок измерения или записи показателя. Затем осуществляется отсеивание сообщений, которые не могут быть достоверными из-за выхода значения какого-либо отдельного параметра (или группы параметров) за допустимые границы. В результате формируется множество:
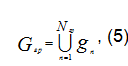
в которое входят только измерения, удовлетворяющие следующему условию:

Решение задачи второго, основного этапа информационной фильтрации заключается в отборе из исходного множества информационных сообщений с оценкой достоверности ![]() выше некоторой значимой величины w0.
выше некоторой значимой величины w0.
Для информации, имеющей численные значения сведений, решением задачи информационной фильтрации является отображение множества информационных сообщений (5) во множество оценок достоверности исходных сообщений:

и формирование множества G ⊆ Gгр отобранных (отфильтрованных) сообщений ![]() по правилу:
по правилу:
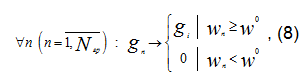
где 0 - некоторое пустое множество.
Как правило, различные показатели измерены в разных единицах измерения. Для эффективной работы алгоритма фильтрации информации необходимо произвести нормировку всех показателей. Нормировка представляет собой переход к некоторому единообразному описанию для всех признаков, к введению новой единицы измерения, допускающей формальные сопоставления объектов.
Наиболее удобна нормировка относительно допустимого диапазона изменения значений показателей. Для задачи (5) она определяется по следующей формуле:

Определение степени достоверности информационных сообщений при решении задачи (7) - (8) основано на концепции типичности, т.е. достоверность wn информационного сообщения считается тем выше, чем оно типичнее для данной ситуации (для всего ряда сообщений). Поскольку сведения из сообщений {Pin} представлены численными значениями, правомерен геометрический подход, позволяющий рассматривать информационные сообщения как «созвездия» в i-мерном гиперпространстве признаков [1]. Способ и адекватность решения зависят от дополнительных априорных данных о степени «засоренности» исходной выборки сообщений Gгр.
Если априорно известно, что выборка Gгр «засорена» мало, то правомерно предположить, что сообщения gn сгруппированы некоторым образом симметрично относительно мнимого центра тяжести и с большей вероятностью наиболее достоверные сообщения располагаются на наименьшем расстоянии от некоторого гипотетического обобщенного сообщения g0 с численным набором сведений:

Решением является вычисление значений вектора расстояний ![]() от сообщений gn ∈ Gгр до обобщенного сообщения g0 с использованием той или иной адекватной по отношению к сведениям метрики, например евклидовой:
от сообщений gn ∈ Gгр до обобщенного сообщения g0 с использованием той или иной адекватной по отношению к сведениям метрики, например евклидовой:

При этом степень достоверности сообщений gn 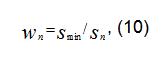 ,
,
где ![]()
Если выборка Gгр «засорена» более значительно, например наполовину, то более правильно предположить асимметрию распределения фактов и тогда понятие обобщенного сообщения g0 не может адекватным образом представить выборку Gгр. В этом случае предлагаются следующие процедуры определения степени достоверности сообщений: с использованием той или иной адекватной по отношению к сведениям метрики, например евклидовой, вычисляются значения вектора суммарных расстояний ![]()
от каждого информационного сообщения до прочих 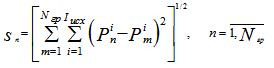
и аналогично (10) определяется степень достоверности сообщений.
Если выборка Gгр сильно «засорена», но есть значимая вероятность того, что группа достоверных информационных сообщений достаточно выражена в смысле гипотезы компактности по отношению к прочим возможным группировкам, то правомерен подход, основанный на классификационном (кластерном) анализе. Предлагаются следующие процедуры определения степени достоверности информации. Если объем выборки Gгр составляет Nгр, то организуется M = Nгр - 2 итерационных цикла с индексами ![]() В каждом итерационном цикле осуществляется классификация выборки Gгр на C классов и для всех итераций подсчитывается hn - суммарное число включений каждого сообщения в классы KC объемом VC≥2
В каждом итерационном цикле осуществляется классификация выборки Gгр на C классов и для всех итераций подсчитывается hn - суммарное число включений каждого сообщения в классы KC объемом VC≥2
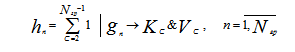
При этом степень достоверности информационного сообщения gn
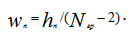
Классификацию выборки сообщений ![]()
на заданное число классов C осуществляется с использованием того или иного адекватного по отношению к сведениям метода «средней связи». Для этого с помощью выбранной метрики, например евклидовой, строят матрицу S взаимных расстояний между сообщениями с элементами матрицы:
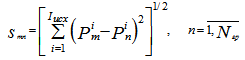
Далее сообщения классифицируются с использованием гипотезы компактности – сходные сообщения в гиперпространстве сведений располагаются в некотором смысле компактно, т.е. расстояния между сообщениями из одного класса меньше расстояний между центрами классов.
Объем множества G отфильтрованных сообщений в значительной мере зависит от установленного значения w0.
Точность моделей, построенных на основе статистических методов в значительной мере зависит от количества учитываемых параметров. Одновременно с увеличением числа параметров значительно возрастают затраты вычислительных ресурсов. Поэтому оптимальный выбор признакового пространства в значительной мере обеспечивает эффективность и качество функционирования алгоритмических схем. Критерием оптимальности является минимизация числа измеряемых параметров при условии обеспечения достаточной информативности выбранной параметрической системы. Степень оптимальности и корректности процедур минимизации определяют надежность и достоверность построенных моделей.
Существует эффективный метод минимизации информативной параметрической избыточности – метод «корреляционных плеяд». Его дальнейшее развитие и машинная адаптация – метод «дискретных корреляционных плеяд» [2]. Суть последнего метода заключается в формировании плеяд параметров со значимым признаком сходства и последующей заменой этих плеяд на единственный (головной) параметр, обладающий наибольшим весом по отношению к прочим.
При этом оказывается возможным установить функциональную зависимость каждого из параметров с головным параметром, что позволяет в дальнейшем судить об их значениях.
В задаче (5) для множества {Pin} значений параметров объектов gn формируется матрица взаимной корреляции, представляющая собой множество значений

где i и j – индексы соответственно строки и столбца матрицы R.
С использованием критерия Спирмена устанавливается порог значимости коэффициента корреляции r0 и осуществляется преобразование исходной матрицы взаимной корреляции R в дискретную корреляционную матрицу ![]() по правилу:
по правилу:
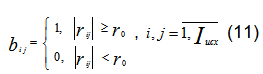
Для каждой строки полученной таким образом матрицы D подсчитываются "веса" параметров Vi
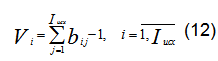
и определяется индекс строки im матрицы B для параметров с максимальным весом ![]() причем если существуют несколько параметров с весом
причем если существуют несколько параметров с весом ![]() то выбирается первый из них.
то выбирается первый из них.
Далее осуществляется формирование im-ой корреляционной плеяды со значимыми дискретными оценками корреляции. В плеяду включаются параметры с индексом j, для которых справедливо 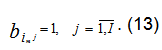 .
.
Строка с индексом im и столбцы с индексами j дискретной корреляционной матрицы B, определяемыми согласно (13), обнуляются, и процесс формирования плеяд повторяется, начиная с определения значений весов параметров согласно (12) до полного обнуления матрицы B.
Данный метод по сравнению с другими методами минимизации информативной избыточности наиболее прост и доступен для алгоритмизации. Его машинная адаптация не является трудоемкой и не влечет за собой значительных вычислительных затрат и ресурсов. Однако ему присущи существенные недостатки, обусловленные следующей причиной: поскольку в данном методе в качестве оценок сходства применяются значения коэффициентов корреляции, то предполагается, что параметры {Pin} объектов gn должны иметь нормальный закон распределения. Данное ограничение является весьма существенным, поскольку зачастую невыполнимо.
Использование в качестве оценок мер сходства непараметрических робастных критериев, например коэффициентов ранговой корреляции Спирмена, также не обеспечивает их адекватности, поскольку данные оценки в ряде случаев являются приближенными.
Наиболее естественно для определения меры сходства (различия) воспользоваться геометрическим подходом. В этом случае сходство двух рядов чисел (значений параметров) отождествляется либо с расстоянием между ними, определенным с использованием той или иной метрики, либо со значением некоторой заранее заданной функции над заранее определенной метрикой. Для определения степени сходства (близости) двух рядов чисел ![]() и
и ![]() представляющих собой значения параметров с индексами i и j
представляющих собой значения параметров с индексами i и j ![]() исходного множества G, можно использовать такие метрические преобразования, как расстояние Махаланобиса, евклидово и взвешенное евклидово, хеммингово расстояние. Степень близости при этом определяется путем сопоставления вычисленных расстояний с каким-то заранее определенным пределом. Объекты считаются похожими, если расстояние между ними не превышает этого предела, в противном случае – непохожими. При данном подходе невозможна строгая формализация понятия меры сходства как меры близости, поскольку степень сходства является зависимой как от значений параметров, так и от значений установленного предела.
исходного множества G, можно использовать такие метрические преобразования, как расстояние Махаланобиса, евклидово и взвешенное евклидово, хеммингово расстояние. Степень близости при этом определяется путем сопоставления вычисленных расстояний с каким-то заранее определенным пределом. Объекты считаются похожими, если расстояние между ними не превышает этого предела, в противном случае – непохожими. При данном подходе невозможна строгая формализация понятия меры сходства как меры близости, поскольку степень сходства является зависимой как от значений параметров, так и от значений установленного предела.
Существует другой подход, основанный на вычислении расстояний в признаковом пространстве с помощью некоторых специально устроенных функций ![]() получивших название потенциальных. Эти функции принимают значение от 0 до 1 в зависимости от «потенциала» объекта
получивших название потенциальных. Эти функции принимают значение от 0 до 1 в зависимости от «потенциала» объекта ![]() по отношению к объекту
по отношению к объекту ![]()
Однако, поскольку при этом ограничений на вид потенциальных функций не накладывается и признаковое пространство не фиксировано и не ограничено, полученные оценки не являются наглядными и так же как и в предыдущем случае не допускают эталонирования меры сходства.
Рассмотрим простую процедуру вычисления оценок степени сходства, свободную от указанных недостатков.
1. Значения признаков ![]() сводятся к единице в целях ограничения и фиксации признакового пространства:
сводятся к единице в целях ограничения и фиксации признакового пространства:
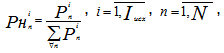
т.е. формируются дискретные распределения признаков ![]() с суммарными весами, равными единице
с суммарными весами, равными единице ![]()
- Аналогично расстоянию по Хэммингу определяется интегральная разница в значениях нормированных признаков распределений по каждой паре:
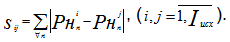
- По каждой паре признаков вычисляется значение степени сходства
 Следует отметить, что коэффициент сходства q в основном аналогичен коэффициенту корреляции. В зависимости от значений признаков он принимает значения от -1 (что эквивалентно утверждению типа «абсолютно противоположен») до +1 (что эквивалентно утверждению типа «абсолютно поход»). Нулевое значение коэффициента q следует интерпретировать как абсолютную непохожесть, т.е. полное отсутствие какого либо сходства.
Следует отметить, что коэффициент сходства q в основном аналогичен коэффициенту корреляции. В зависимости от значений признаков он принимает значения от -1 (что эквивалентно утверждению типа «абсолютно противоположен») до +1 (что эквивалентно утверждению типа «абсолютно поход»). Нулевое значение коэффициента q следует интерпретировать как абсолютную непохожесть, т.е. полное отсутствие какого либо сходства.
Данная аналогия позволяет осуществить эквивалентную замену в методе дискретных корреляционных плеяд коэффициента корреляции на приведенную непараметрическую оценку степени сходства.
Информация, прошедшая этапы фильтрации и исключения параметрической избыточности может быть использована для построения моделей медицинских систем различного уровня.